
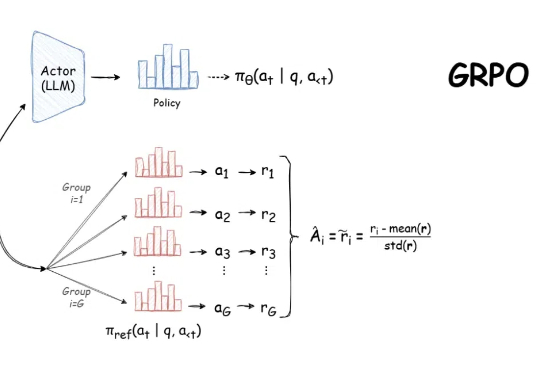
DeepSeek用的GRPO占用大量内存?有人给出了些破解方法
DeepSeek用的GRPO占用大量内存?有人给出了些破解方法自 DeepSeek-R1 发布以来,群组相对策略优化(GRPO)因其有效性和易于训练而成为大型语言模型强化学习的热门话题。R1 论文展示了如何使用 GRPO 从遵循 LLM(DeepSeek-v3)的基本指令转变为推理模型(DeepSeek-R1)。
来自主题: AI技术研报
7637 点击 2025-02-07 16:53
自 DeepSeek-R1 发布以来,群组相对策略优化(GRPO)因其有效性和易于训练而成为大型语言模型强化学习的热门话题。R1 论文展示了如何使用 GRPO 从遵循 LLM(DeepSeek-v3)的基本指令转变为推理模型(DeepSeek-R1)。

近日,资深机器学习研究科学家 Cameron R. Wolfe 更新了一篇超长的博客文章,详细介绍了 LLM scaling 的当前状况,并分享了他对 AI 研究未来的看法。

「除了 Claude、豆包和 Gemini 之外,知名的闭源和开源 LLM 通常表现出很高的蒸馏度。」这是中国科学院深圳先进技术研究院、北大、零一万物等机构的研究者在一篇新论文中得出的结论。

对 LLM 来说,Pre-training 的时代已经基本结束了。视频模型的 Scaling Law,瓶颈还很早。具身智能:完全具备人类泛化能力的机器人,在我们这代可能无法实现
Grok AI 最近网页版刚刚上线。我看到不少人都在比较 Grok 对标 ChatGPT 等等 LLM 大模型的研究和生成能力。我想说,背靠 X (前推特)数据库的 Grok AI,最好的使用方式难道不是实时监测全球媒体热点吗?
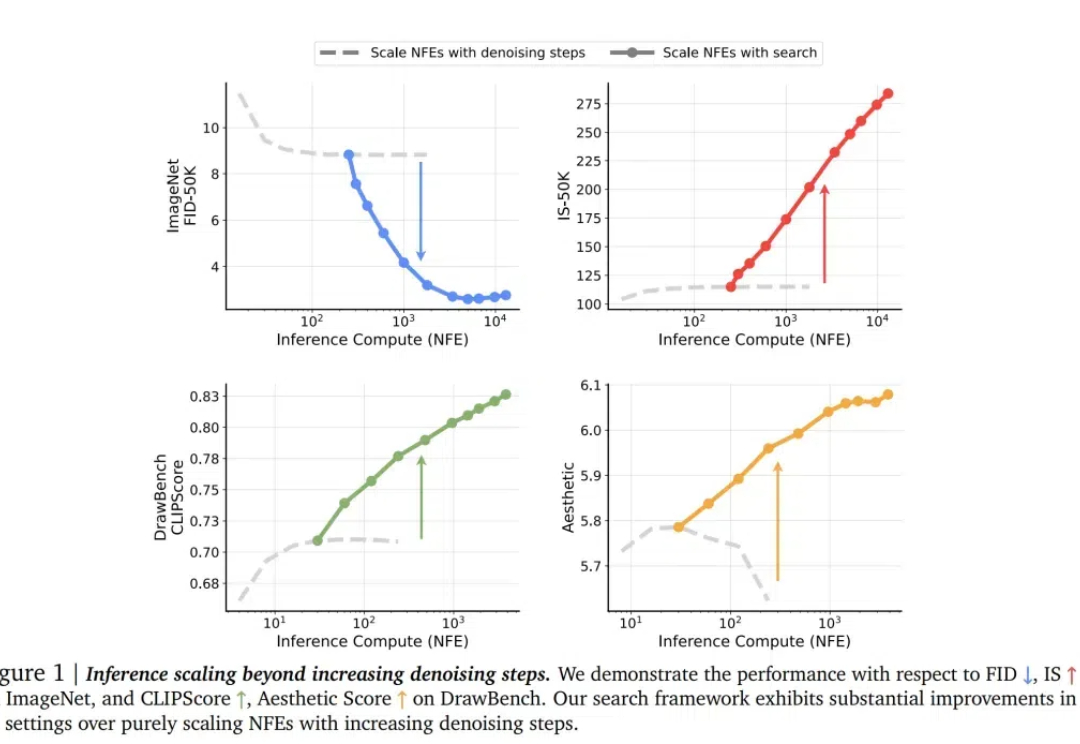
对于 LLM,推理时 scaling 是有效的!这一点已经被近期的许多推理大模型证明:o1、o3、DeepSeek R1、QwQ、Step Reasoner mini……
自适应 LLM 反映了神经科学和计算生物学中一个公认的原理,即大脑根据当前任务激活特定区域,并动态重组其功能网络以响应不断变化的任务需求。
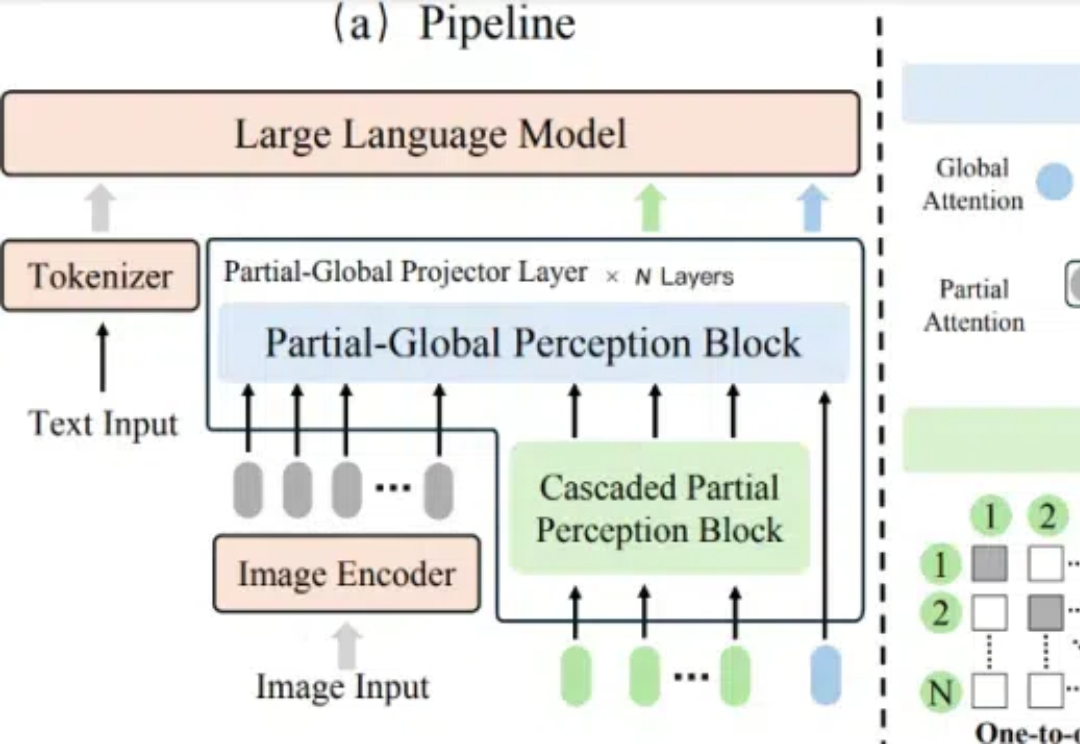
在多模态大语言模型(MLLMs)的发展中,视觉 - 语言连接器作为将视觉特征映射到 LLM 语言空间的关键组件,起到了桥梁作用。
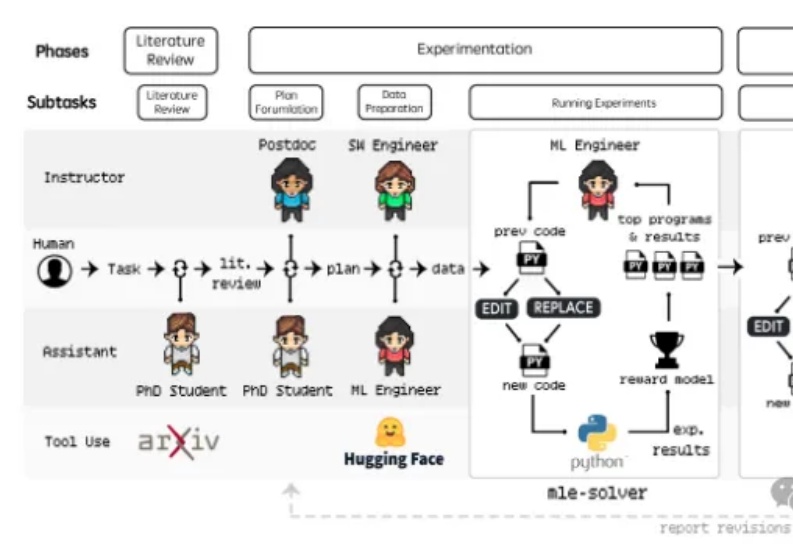
发表于昨天的论文《Agent Laboratory: Using LLM Agents as Research Assistants》对于科研界具有划时代意义,过去几周才能完成的科研任务现在仅需20分钟到一两个小时左右(不同LLM),花费2-13个美金的Token即可完成!
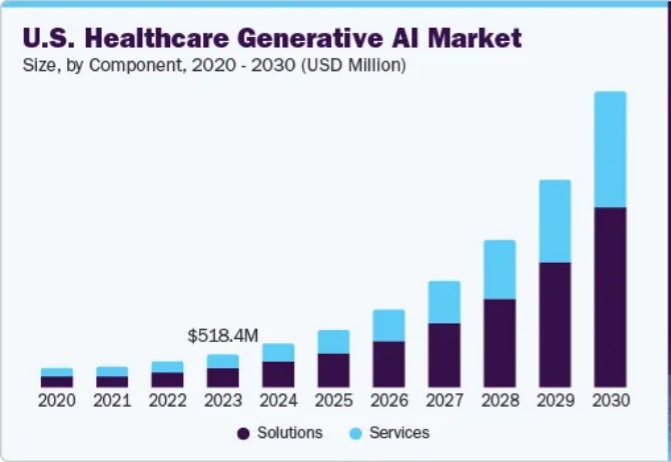
在 LLM 落地场景中,医疗领域的应用开始展现出比较高的确定性,尤其是 AI scribe 产品能解决临床文档记录枯燥、耗时这一行业痛点。Abridge 是其中最有代表性的公司,训练了专用于临床文档的 ASR 和文本生成模型,能够替代 90% 左右的人工工作量。